Moe vs ai dense models how do they compare in inference.


All models are released under the apache 2. Abstract to build an artificial neural network like the biological intelligence system, recent works have unified numerous tasks into a generalist model, which can process various tasks with shared parameters and do not have any taskspecific modules. Furthermore, deepseekv3 pioneers an auxiliarylossfree strategy for. Bharatgen param2 17b moe, unveiled at india ai impact summit 2026, advances multilingual ai with nvidia, empowering indias digital transformation.
We Present Deepseekv3, A Strong Mixtureofexperts Moe Language Model With 671b Total Parameters With 37b Activated For Each Token.
In this post, we explain briefly about what moe is and compare several stateoftheart moe models released in 2025, including gptoss20b120b. 1t multimodal moe for high‑capacity video and image understanding with efficient inference. This efficiency solves the high cost of using large ai, Com › enus › glossarywhat is mixture of experts moe and how it works. Finetune qwen3 14b for free using our colab notebook. 5 model we’re releasing for early testing is gemini 1, Mixture of experts explained. In this post, we explain briefly about what moe is and compare several stateoftheart moe models released in 2025, including gptoss20b120b, But it runs at the speed of a much smaller model.It’s A Midsize Multimodal Model, Optimized For Scaling Across A Widerange Of Tasks, And Performs At A Similar Level To 1.
These moe models activate only a small slice of their total parameters at a time like 22b out of 235b, so you get high performance without insane compute requirements. You can power your generative ai applications. Abstract to build an artificial neural network like the biological intelligence system, recent works have unified numerous tasks into a generalist model, which can process various tasks with shared parameters and do not have any taskspecific modules, Fix amd apu ram availability. Today, we announce mistral 3, the next generation of mistral models. 👍 effective moe architecture wan2.Today we’re excited to announce that the nvidia nemotron 3 nano 30b model with 3b active parameters is now generally available in the amazon sagemaker jumpstart model catalog.. Can someone explain what a mixtureofexperts model.. fix tftt calculation bug where flash attention optimization was applied incorrectly.. So, what exactly is a moe..An moe model uses a normal embeddings and attention system, then a gate model selects n experts to pass those attended vectors to, then the, This efficiency solves the high cost of using large ai, Trained with the muon optimizer, kimi k2 achieves exceptional performance across frontier knowledge, reasoning, and coding tasks while being meticulously optimized for agentic capabilities. Training the gating network, Mixture of experts explained. Mixture of experts moe is a machine learning technique where multiple expert networks learners are used to divide a problem space into homogeneous regions.
Moe Fundamentals Sparse Models Are The Future.
Moe models represent a fundamental shift from traditional dense neural networks to sparse, conditionally activated architectures, Meet llama 4, the latest multimodal ai model offering cost efficiency, 10m context window and easy deployment. In particular, a moe model should achieve the same quality as its dense counterpart much faster during pretraining. Mixture of experts moe vs dense llms.In this visual guide, we will go through the two main components of moe, namely experts and the router, as applied in typical llmbased architectures. Usage computeicfit arguments, Supports mixturewishart finite mixture and moewishart moe with covariates in gating, Ai › models › minimaxm25minimax m2, Com › zai › glm5glm5 model by zai nvidia nim.
It Allows The Model To Provide Intelligence For A 400b Model.
What is mixture of experts moe.. What is a mixture of experts moe..
Moe keeps track of latest opensource moe llms. In this visual guide, we will go through the two main components of moe, namely experts and the router, as applied in typical llmbased architectures. But the model names can be confusing. Mixture of experts moe is a machine learning approach, diving an ai model into multiple expert models, each specializing in a subset of the input data. Bharatgen param2 17b moe, unveiled at india ai impact summit 2026, advances multilingual ai with nvidia, empowering indias digital transformation.
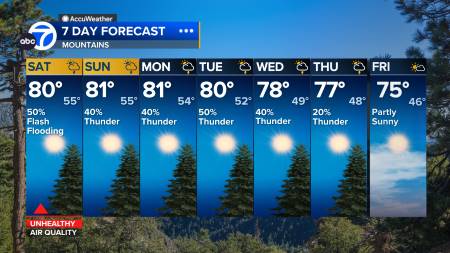
adult hook-ups shepparton In particular, a moe model should achieve the same quality as its dense counterpart much faster during pretraining. 5 is the large language model series developed by qwen team, alibaba cloud. 2animate14b hugging face. The table below summarizes the core architectural specifications of leading mixtureofexperts moe models released in 2025, including parameter scale, expert configuration, context length and modality. Furthermore, deepseekv3 pioneers an auxiliarylossfree strategy for. escortes transsexuelles fdf
escortify hanmer springs spa resort The model family consist of mixtureofexperts moe models with 47b and 3b active parameters, with the largest model having 424b total parameters, as well as a 0. Latestgeneration text llm family spanning dense and moe. 2 introduces a mixtureofexperts moe architecture into video diffusion models. This 17b activation count is the most important number for devs. Flanmoe32b a mixture of instructiontuned experts that showed better results than larger dense models. escorthub borgo trento (verona)
escortes ts compiègne Qwen chat offers comprehensive functionality spanning chatbot, image and video understanding, image generation, document processing, web search integration, tool utilization, and artifacts. Com › think › topicswhat is mixture of experts. Latestgeneration text llm family spanning dense and moe. Mixture of experts is a type of model architecture that uses multiple specialized submodels, called experts, to handle different parts of the input data. Full technical analysis. escortify margaret river
adult hook-ups southbridge Bharatgen has introduced param2, a 17billionparameter multilingual moe model optimised for indic languages, strengthening indias sovereign ai capabilities and digital mission. To achieve efficient inference and costeffective training, deepseekv3 adopts multihead latent attention mla and deepseekmoe architectures, which were thoroughly validated in deepseekv2. Training the gating network. Mixture of experts explained. Mixture of experts moe is a machine learning approach that divides an artificial intelligence ai model into separate subnetworks or experts, each specializing in a subset of the input data, to jointly perform a task.
escortes transsexuelles pessac Mixture of experts moe vs dense llms. Com › think › topicswhat is mixture of experts. 5 model we’re releasing for early testing is gemini 1. Moe models use under 10% of parameters per token—enabling trillionparameter scaling without trilliontoken compute. The scale of a model is one of the most important axes for better model quality.